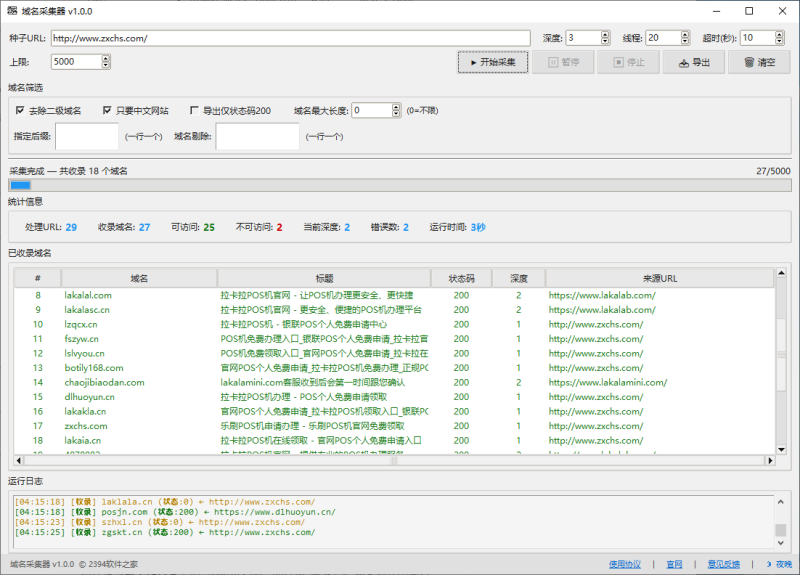
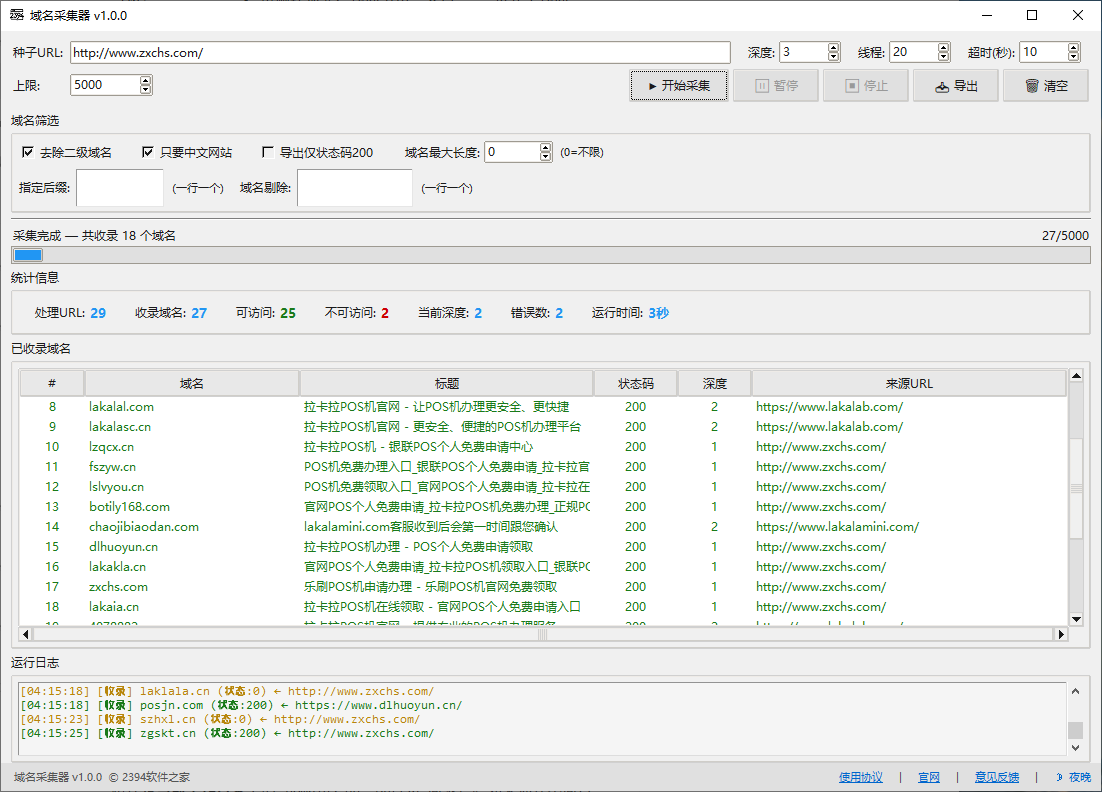
域名采集器是一款基于裂变式蜘蛛网算法的域名发现工具。输入一个种子URL,它会像蜘蛛织网一样逐层发现该网站引用的所有外部域名,自动去重、筛选、导出,帮你快速建立垂直领域的域名库。
大白话:给它一个网址,它帮你挖出这个网站链接了哪些其他网站。
版本说明
v1.0.0 (2026-06-15)
✨ 核心采集
- 裂变式蜘蛛网爬取引擎,从种子URL逐层发现外部域名
- 多线程并发抓取,线程数1~25可调
- 深度1~10层可配,域名上限100~100,000可控
- SQLite本地持久化,关软件不丢数据
- 全局去重:URL级+域名级双重去重,不重复采集
- 暂停/继续/停止,随时控制采集节奏
🔧 域名筛选
- 去除二级域名——自动合并子域名
- 只要中文网站——自动检测页面中文内容
- 域名最大长度限制——过滤超长域名
- 指定后缀白名单——只保留特定后缀(.com/.cn/.net 等)
- 域名剔除黑名单——排除不想要的域名
📤 数据导出
- CSV格式导出,含完整字段(序号、域名、URL、标题、状态码、深度、来源)
- TXT格式导出,仅含可访问域名,一行一个
- 导出仅状态码200——一键过滤死链和错误页面
🎨 双主题
- 白天/夜晚两套完整配色,一键切换
- 覆盖约40个色值,阅读舒适
💾 配置持久化
- 所有设置自动保存到
config.ini,重启恢复 - 包括筛选规则、线程数、深度、导出偏好等
🖥️ 其他
- 使用协议弹窗,合规使用声明
- 底部栏快捷跳转:官网、意见反馈
- 实时统计面板:总域名、可访问、不可访问
- 彩色日志分级显示(信息/成功/警告/错误)
使用教程
第一步:启动软件
双击 域名采集器_v1.0.0.exe,弹出使用协议弹窗,点击「同意」 进入主界面。
第二步:输入种子URL
在「种子URL」输入框中,填入你要采集的目标网址,例如:
code复制
https://www.example.com
⚠️ URL必须以
http://或https://开头,否则会有提示。
第三步:设置采集参数
| 参数 | 说明 | 建议值 |
|---|---|---|
| 深度 | 从种子URL逐层爬取的最大层数 | 3~5层即可覆盖大部分外部链接 |
| 线程 | 同时抓取的并发数 | 15~20,网站性能差的可调低 |
| 超时 | 每个请求最大等待时间 | 10秒,网络差可加大 |
| 上限 | 最多收录域名数 | 5000,按需调整 |
第四步:配置筛选规则(可选)
根据需要启用筛选条件:
- 去除二级域名:把
news.example.com合并为example.com - 只要中文网站:通过检测页面中文字符,过滤非中文网站
- 域名最大长度:过滤超长域名(0=不限)
- 指定后缀:在文本框里一行写一个后缀,只保留匹配的域名(如
com、cn) - 域名剔除:在文本框里一行写一个域名,采集时跳过这些域名
💡 筛选规则在采集过程中实时生效,勾选即过滤,无需重启。
第五步:开始采集
点击 ▶ 开始采集,进度条开始滚动,日志区实时输出采集动态:
code复制
[信息] === 开始采集 ===
[信息] 种子URL: https://www.example.com
[信息] 最大深度: 3, 线程数: 20, 超时: 10秒
[成功] www.example2.com | 标题: 示例网站 | 深度: 1 | 200
[成功] www.example3.cn | 标题: 中文示例 | 深度: 1 | 200
...
采集过程中可随时:
- 点击 ⏸ 暂停 暂停抓取
- 点击 ⏹ 停止 终止采集
第六步:导出结果
采集完成后(或手动停止后),点击 📥 导出结果:
- 选择保存目录
- 自动生成带时间戳的两个文件:
域名采集_20260615_153022.csv— 完整数据表格域名采集_20260615_153022.txt— 纯域名列表
💡 如果只需要状态码200的有效网址,勾选「导出仅状态码200」后再导出。
第七步:清空重来
点击 清空,数据库和表格全部重置,可重新开始采集。
功能说明
🕸️ 裂变式蜘蛛网算法
code复制
种子 URL (深度0)
├── 发现 link1 → 访问 → 提取该页面的所有外部链接 (深度1)
│ ├── 发现 link1-1 (深度2)
│ │ └── ...
│ └── 发现 link1-2 (深度2)
├── 发现 link2 (深度1)
└── 发现 link3 (深度1)
每个页面被访问后,引擎从HTML中提取所有外部链接,放入对应深度的队列,由多线程工作池并发处理。整个过程像一个不断扩大的蛛网,直到达到深度上限或无新域名为止。
🔗 双重去重
- URL级去重:同一个URL不会被重复访问
- 域名级去重:同一个域名(不同页面)不会重复入库
- 历史去重:启动时加载
domains.db已有域名,避免跨会话重复
🗄️ SQLite 持久存储
- 所有采集数据存在
domains.db中 - 下次打开软件,历史数据自动显示在表格中
- 删掉
domains.db即可完全重置
🎨 双主题配色
| 主题 | 适用场景 |
|---|---|
| ☀️ 白天 | 日常办公、明亮环境 |
| 🌙 夜晚 | 深夜使用、护眼模式 |
一键切换,所有40+颜色值同步更新。
使用场景
1. 竞争对手域名调研
输入竞争对手官网URL,快速发现其关联的合作伙伴网站、友链、联盟站点,绘制竞争版图。
2. SEO外链分析
分析某个行业门户的友情链接生态,获取高质量外链来源列表,辅助SEO外链策略制定。
3. 垂直行业域名库建设
选定一个行业门户种子站,设置深度3~5,自动采集行业内所有关联域名,建立行业域名资产库。
4. 网络安全资产测绘
输入企业主站URL,通过爬取发现其关联子站、服务商、CDN节点域名,绘制企业互联网资产地图。
5. 大数据采集预处理
作为爬虫项目的前置步骤,先用域名采集器快速发现目标域名单,再对每个域名做精细化采集,避免盲目搜索。
6. 内容聚合与收录监控
输入内容聚合站或导航站URL,持续监控其新增收录的站点,第一时间发现新内容源。
下载地址
免责声明
本软件仅供合法的网络研究与数据采集使用。使用者须遵守目标网站的 robots.txt 协议及相关法律法规,不得用于非法爬取、侵犯隐私、盗用数据等违法行为。作者不承担因使用本软件产生的任何法律责任。
💬 意见反馈:2394.cn/forum/58.html 🌐 官网:2394.cn 📅 最后更新:2026-06-15
📌 售后说明
一、关于虚拟产品
本产品为数字虚拟商品(Windows应用程序),一经发送下载链接,即视为交付完成。根据虚拟商品特性,本产品不支持退款,请购买前仔细了解产品功能。
二、售后服务范围
购买后凭订单号可享受以下服务:
- 📦 产品下载链接获取
- 🔄 后续版本免费更新
- ❓ 软件使用问题咨询(非教学指导)
三、服务保障
我们提供以下保障:
- 🔒 数据安全:API Key仅保存在本地,不上传任何服务器
- 🔧 持续更新:版本持续迭代,修复问题、新增功能
- 💬 售后沟通:通过官网 https://2394.cn/forum/58.html 反馈问题
四、免责声明
本工具仅提供文章生成功能,用户需自行确保使用AI生成内容的合法合规性,包括但不限于版权、原创性、平台规则等。开发者不对用户使用本产品产生的任何法律风险承担责任。
暂无评价内容