
一、软件简介
域名采集器 是一款智能域名发现工具。你只需要给它一个网址(种子URL),它就会像蜘蛛织网一样,自动一层一层地发现这个网站引用的所有其他网站域名,最终帮你整理出一份完整的域名列表。
域名采集器
举个例子: 你想知道某个行业门户网站都链接了哪些其他网站,只需把门户网址输入进去,点一下开始,软件会自动帮你全部找出来。
二、界面介绍
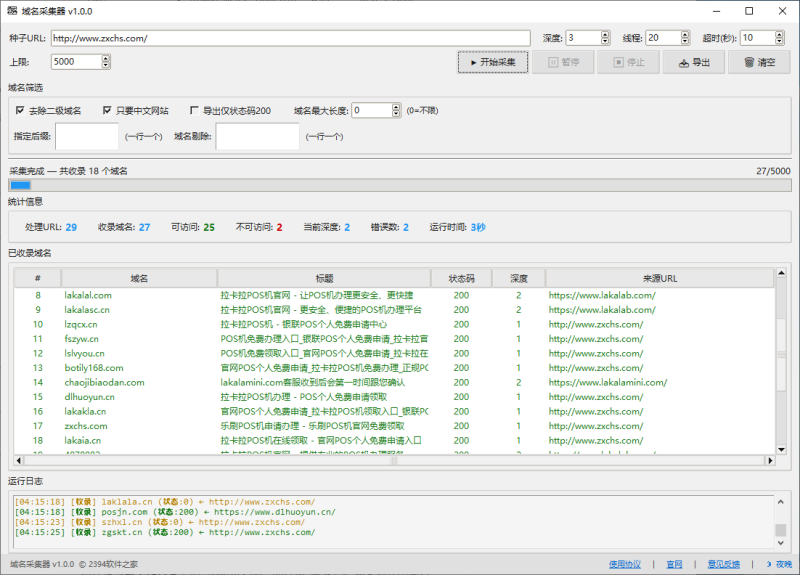
打开软件后,主界面从上到下分为5个区域:
![图片[1]-域名采集器 — 用户使用教程-2394 软件之家](https://2394.cn/wp-content/uploads/2026/06/QQ20260615-041537-1024x736.png)
① 控制栏(顶部)
这里设置采集的核心参数:
| 设置项 | 在哪里 | 干什么用 |
|---|---|---|
| 种子URL | 输入框 | 你要从哪个网址开始爬 |
| 深度 | 数字选择器 | 爬几层链接(1=只爬当前页面外链,3=层层递进) |
| 线程 | 数字选择器 | 同时几个线程干活,数字越大越快但占资源 |
| 超时 | 数字选择器 | 每个网页最多等几秒,超时就跳过 |
| 上限 | 数字选择器 | 最多收录多少个域名,到了就停 |
② 域名筛选(中部第一区)
标签为「域名筛选」,用于过滤不想保留的域名:
| 筛选项 | 类型 | 作用 |
|---|---|---|
| 去除二级域名 | 勾选框 | 把 news.example.com 合并为 example.com |
| 只要中文网站 | 勾选框 | 只保留页面含中文的域名 |
| 导出仅状态码200 | 勾选框 | 仅导出HTTP 200的正常网页(不影响采集) |
| 域名最大长度 | 数字选择器 | 域名超过这个长度的不要,0=不限 |
| 指定后缀 | 文本框 | 一行写一个后缀,只保留匹配的 |
| 域名剔除 | 文本框 | 一行写一个域名,这些域名不收录 |
③ 统计面板(中部第二区)
实时显示采集数据:
- 总域名:已发现并入库的域名数
- 可访问:HTTP状态码正常的域名数
- 不可访问:无法访问或状态码异常的域名数
- 错误:请求失败的次数
- 进度条:采集运行时滚动显示
④ 结果表格(中部第三区)
以表格形式展示每条采集结果,包含:序号、域名、完整URL、页面标题、状态码、深度、来源URL、是否可访问、发现时间。
⑤ 日志区(底部)
以不同颜色显示运行日志:
- 🟢 绿色 = 成功
- 🟡 黄色 = 警告
- 🔴 红色 = 错误
- 🔵 蓝色 = 信息
三、操作按钮说明
界面上的操作按钮及功能:
| 按钮 | 功能 |
|---|---|
| ▶ 开始采集 | 开始从种子URL爬取域名 |
| ⏸ 暂停 | 暂停当前采集(可继续) |
| ⏹ 停止 | 终止当前采集 |
| 📥 导出结果 | 将采集到的域名导出为CSV和TXT文件 |
| 🗑 清空 | 清空数据库和表格,恢复初始状态 |
底部栏:
- 使用协议:查看免责声明
- 2394软件之家:跳转官网
- 意见反馈:跳转论坛反馈页
- ☀/🌙:切换白天/夜晚主题
四、基础操作流程
第 1 步:输入种子URL
在「种子URL」输入框中输入目标网址,例如:
code复制
https://www.xxx.com
⚠️ 必须包含
http://或https://前缀。
第 2 步:设置采集参数
根据需求调整参数:
新手建议:
- 深度:3(太深会跑很久)
- 线程:15(平衡速度和资源)
- 超时:10(足够了)
- 上限:5000(一般够用)
深入调研时:
- 深度:5~8
- 线程:20~25
- 上限:10000+
第 3 步:配置筛选规则(可选)
去除二级域名
勾选后,blog.example.com、shop.example.com 都会合并为 example.com,避免同一主域的重复记录。
只要中文网站
勾选后,软件会检测每个页面的内容是否包含中文。不含中文的纯英文站会被自动跳过。适用于只关心国内网站的调研场景。
域名最大长度
设置一个数字,域名超过该长度的不会被收录。比如设 20,则 www.abcdefghijklmnopqrstuvwxyz.com 会被跳过。
指定后缀
在文本框中一行写一个后缀(不含点),例如:
code复制
com
cn
net
org
则只有 .com、.cn、.net、.org 结尾的域名会被保留。
域名剔除
在文本框中一行写一个要排除的域名,例如:
code复制
google.com
facebook.com
baidu.com
采集时遇到这些域名会自动跳过。
💡 以上筛选规则在采集过程中实时生效,勾选或修改后立即应用。
第 4 步:点击开始采集
点击 ▶ 开始采集,进度条开始滚动,日志区会显示:
code复制
[信息] === 开始采集 ===
[信息] 种子URL: https://www.xxx.com
[成功] www.target1.com | 标题: XX官网 | 深度: 1 | 200
[成功] www.target2.cn | 标题: XX中文站 | 深度: 1 | 200
[警告] www.deadlink.com | 错误: 连接超时 | 深度: 2
第 5 步:等待或干预
采集过程中可以:
- 点 ⏸ 暂停:暂时停止抓取,想继续时再点一下
- 点 ⏹ 停止:彻底终止采集,已收录的域名保留
第 6 步:导出结果
采集完成后,点击 📥 导出结果,选择保存目录。
软件会自动生成两个文件:
CSV 文件(域名采集_20260615_153022.csv):
- 用 Excel 或 WPS 打开
- 包含:序号、域名、完整URL、标题、状态码、深度、来源URL、是否可访问、发现时间
TXT 文件(域名采集_20260615_153022.txt):
- 用记事本打开
- 每行一个域名(仅可访问的域名)
💡 如果勾选了「导出仅状态码200」,导出的CSV和TXT都只会包含状态码为200的记录。采集时所有状态码都会入库,勾选只影响导出。
第 7 步:清空重置(可选)
如果想清空所有数据重新采集,点击 🗑 清空,数据库和表格全部重置。
五、常见使用场景
场景 1:调研竞争对手外链
目标: 找出竞争对手官网链接了哪些合作网站
设置:
- 种子URL:竞争对手官网
- 深度:3
- 勾选「只要中文网站」
- 采集完成后导出CSV分析
场景 2:建立行业域名库
目标: 收集某个行业的所有相关网站域名
设置:
- 种子URL:行业门户站首页
- 深度:5
- 上限:10000
- 勾选「去除二级域名」
- 在「指定后缀」里写
com、cn
场景 3:发现新内容源
目标: 从一个导航站或聚合站发现新网站
设置:
- 种子URL:导航站或聚合站URL
- 深度:1(只看导航站链接的直接目标)
- 线程:20
- 导出TXT即可得到网址清单
六、高级技巧
1. 断点续采
数据库 domains.db 会永久保存所有采集结果。下次打开软件时,之前的采集数据会自动加载到表格中。如果上次采集被中断,重新点击开始会从上次未采集的URL继续。
2. 控制采集规模
- 先设深度 2、上限 500 跑一次,看看量级
- 确认目标后加大深度和上限做全量采集
- 避免一上来就设深度 10、上限 100000,可能跑几个小时
3. 自定义后缀筛选
「指定后缀」支持任意后缀:
- 通用TLD:
com、cn、net、org、cc - 行业TLD:
edu(教育)、gov(政府) - 国别TLD:
jp、kr、uk、de
4. 筛选「有效域名」
勾选「导出仅状态码200」后导出,可以一键过滤掉:
- 404 页面(不存在)
- 500 错误(服务器异常)
- 超时/断连的域名
- 重定向异常的域名
七、常见问题
Q:为什么有些网站显示「连接超时」?
A: 对方网站响应慢或网络不通。可以加大「超时」参数(如 15~30 秒),或换一个网络环境。
Q:为什么采集到的域名很少?
A: 检查几点:
- 种子URL的网站本身外部链接少(如单页面站)
- 勾选了过多筛选条件,大部分域名被过滤了
- 深度设置太浅(设 1 就只能爬一层)
Q:显示「SSL证书错误」怎么办?
A: 对方网站的HTTPS证书过期或无效,软件会自动跳过,不影响其他域名采集。
Q:采集过程中软件卡住了?
A: 少数网站响应极慢会拖慢线程。点「停止」终止后,可加大超时参数重新开始。
Q:数据存在哪里?换电脑能带走吗?
A: 数据存在软件同目录下的 domains.db 和 config.ini。把这两个文件和 .exe 一起复制到新电脑即可。
Q:能不能同时采集多个种子URL?
A: 当前版本每次只支持一个种子URL。需要多站点可分别采集后合并导出文件。
八、注意事项
- 合规使用:遵守目标网站的
robots.txt协议,不要对禁止爬取的站点使用 - 请求频率:线程数不要设太高,避免给对方服务器造成压力
- 数据安全:采集到的域名仅供个人分析使用,不得用于非法用途
- 网络环境:部分国外网站可能需要科学上网才能访问
💬 遇到问题?前往 2394.cn/forum/58.html 留言反馈 🌐 官网:2394.cn
暂无评论内容